This article is perfect for you if you are a beginner or intermediate machine learning engineer or data scientist. You’ve already selected your preferred machine learning library like PyTorch or TensorFlow, and mastered choosing the right architecture for your model. You can also train a model and tackle real-world problems. But what’s next?
In this article, I’ll reveal five libraries that I believe every machine learning engineer and data scientist should be familiar with. These will be a valuable addition to your skill set, making you a more competitive candidate and simplifying the machine learning development process.

1. MLFlow — experiment and model tracking
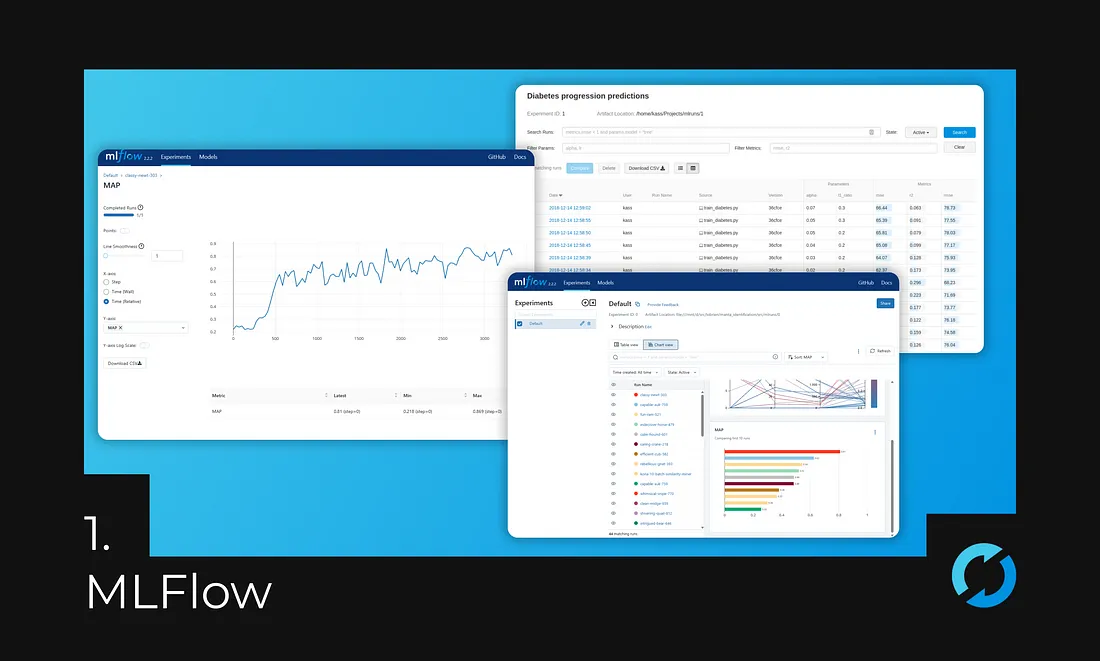
Imagine you’re an ML developer working on a project to build a model that predicts customer churn. You start by exploring your data using Jupyter notebooks, experimenting with different algorithms and hyperparameters. As you progress, your notebooks become increasingly cluttered with code, results, and visualizations. It becomes difficult to track your progress, identify what worked and what didn’t, and replicate your best results.
This is where MLflow comes in. MLflow is a platform that helps you manage your ML experiments from start to finish, ensuring traceability and reproducibility. It provides a centralized repository for storing your code, data, and model artifacts, along with a tracking system that records all your experiments, including hyperparameters, metrics, and outputs.
Here’s how MLflow helps you avoid the pitfalls of using Jupyter notebooks alone:
Centralized Repository: MLflow keeps your code, data, and model artifacts organized and easily accessible. You can quickly find the resources you need without getting lost in a maze of notebooks.
Experiment Tracking: MLflow records every experiment, including the exact code, data, and hyperparameters used. This allows you to easily compare different experiments and identify what led to the best results.
Reproducibility: MLflow makes it possible to reproduce your best models with the exact same code, data, and environment. This is crucial for ensuring the consistency and reliability of your results.
So, if you’re serious about building effective machine learning models, ditch the Jupyter notebook chaos and embrace the power of MLflow.
2. Streamlit — quick and pretty web applications
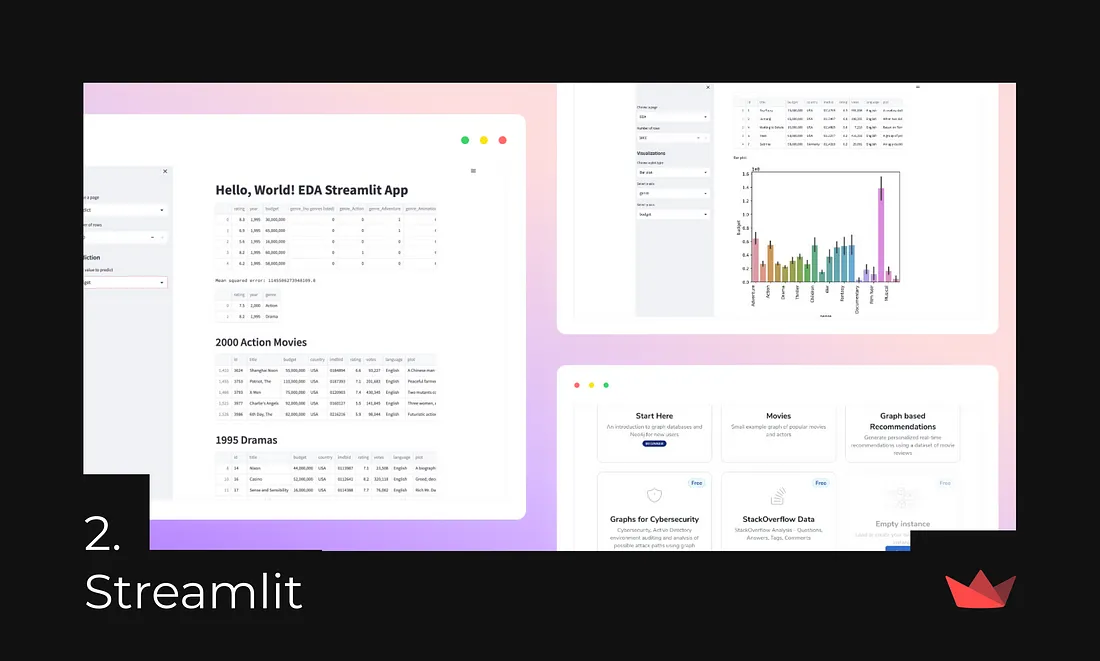
Streamlit is the most popular Frontend framework for Data Science. It is an open-source Python framework. It allows users to create interactive data apps rapidly and with ease, making it particularly beneficial for data scientists and machine learning engineers who may not have extensive web development knowledge.
With Streamlit, developers can build and share attractive user interfaces and deploy models without requiring in-depth front-end experience or knowledge. The framework is free, all-Python, and open-source, enabling the creation of shareable web apps in minutes.
If you have some pet project involving machine learning, a good idea would be adding an interface to it using Streamlit. It takes no time to start working with it, there are many templates ready, and you can finish your frontend in minutes. It’s also extremely easy to share it, meaning it will definitely look good in your resume.
If you want to look into other frontend libraries in Python, be sure to check out my article Top-5 Python Frontend Libraries for Data Science.
3. FastAPI — deploy your models easily and quickly
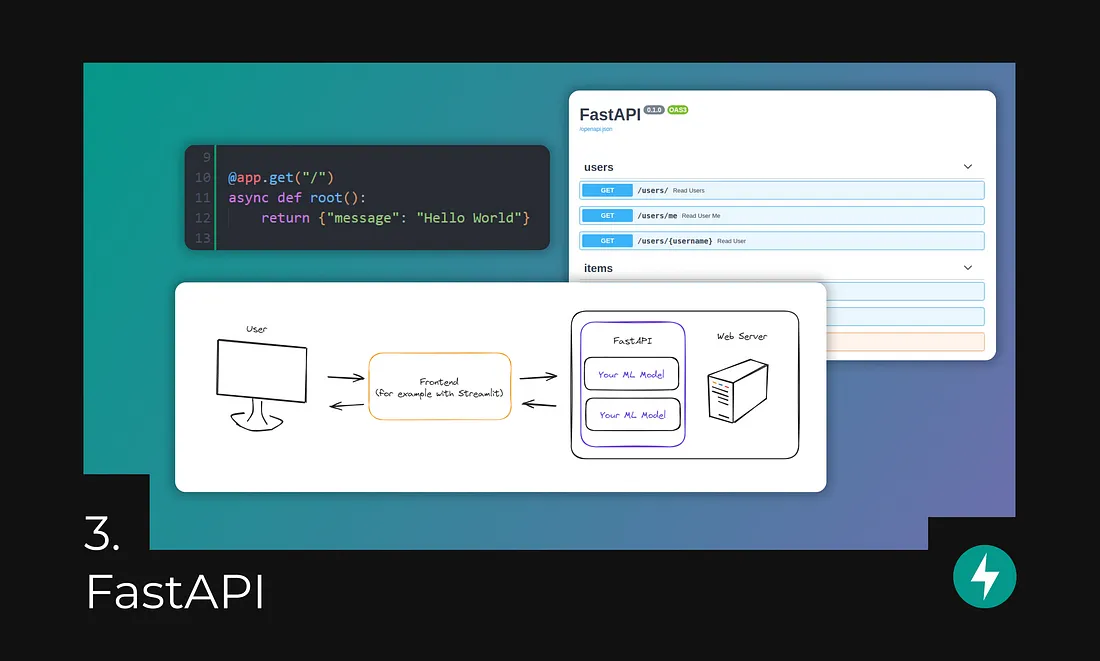
Once you’ve trained and validated your model, you need to deploy it so that it can be used by other applications. This is where FastAPI comes in.
FastAPI is a high-performance web framework for building RESTful APIs. It’s known for its simplicity, ease of use, and speed. This makes it an ideal choice for deploying machine learning models to production.
Here are some of the reasons why ML engineers and data scientists should learn FastAPI:
Speed: FastAPI is incredibly fast. It uses a modern asynchronous programming model that makes it efficient at handling multiple requests simultaneously. This is essential for deploying machine learning models that need to process large amounts of data.
Simplicity: FastAPI is easy to learn and use. It has a clear and concise syntax that makes it easy to write clean and maintainable code. This is important for ML engineers and data scientists who are not necessarily experienced web developers.
Ease of use: FastAPI provides a lot of features that make it easy to build and deploy APIs. For example, it has built-in support for automatic documentation, data validation, and error handling. This saves time and effort, allowing ML engineers to focus on their core work of building and deploying models.
Production-ready: FastAPI is designed for production use. It has features like support for multiple backends, security, and deployment tools. This makes it a reliable choice for deploying critical machine learning models.
In conclusion, FastAPI is a powerful and versatile tool that can be used to deploy machine learning models to production. Its ease of use, speed, and production-readiness make it an ideal choice for ML engineers and data scientists who want to make their models accessible to others.
Comments
Post a Comment